About
Summary
Web app built with Flask that given a stock ticker will scrape dozens of articles off of Nasdaq.com and run them through a machine learning model for analysis.

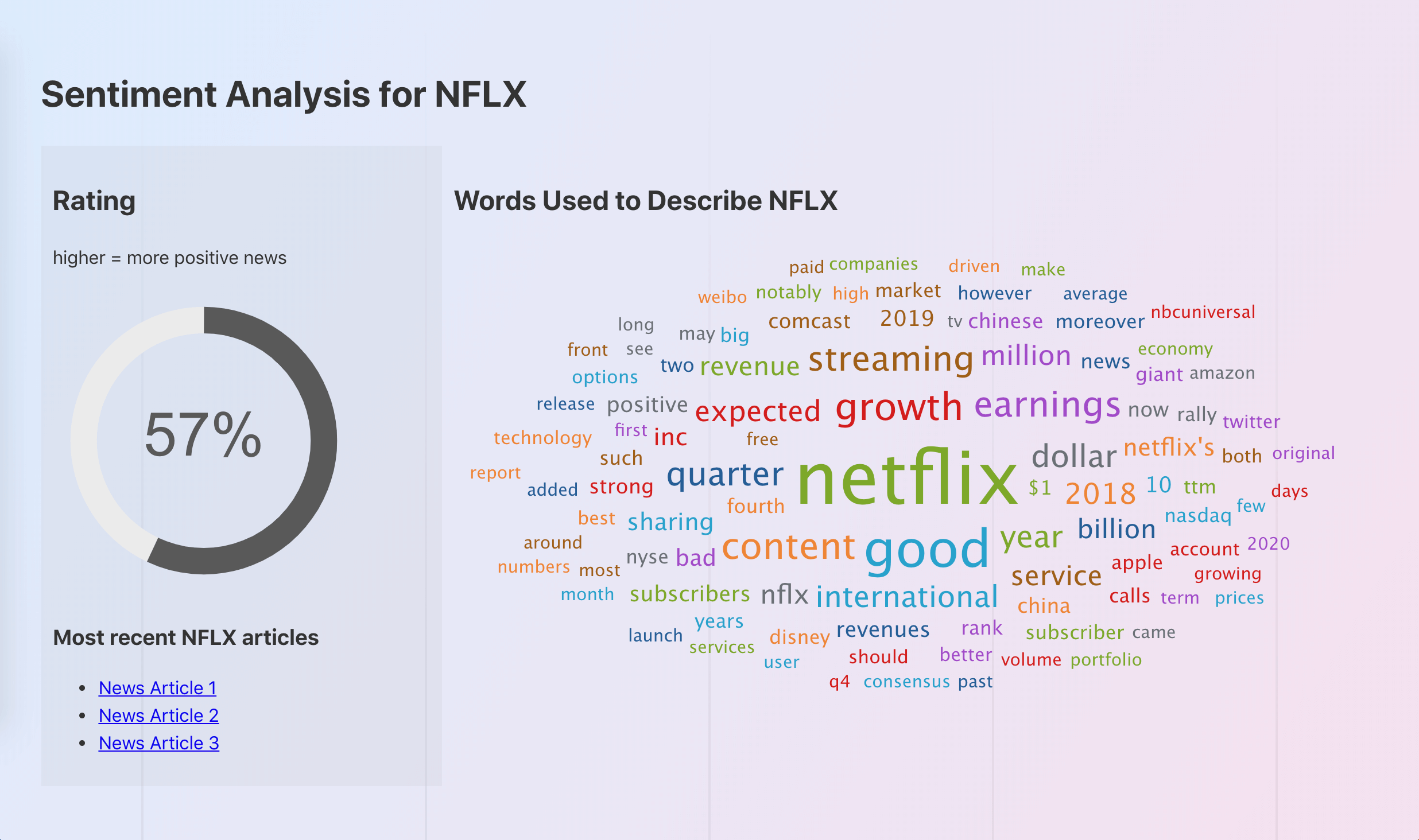
Installation & Usage
Github Repo
# You will need to have Python 3 and Pip installed
$ git clone https://github.com/ianramzy/stock-news-analysis
$ cd stock-news-analysis
$ pip install -r requirements.txt
$ python3 app.py
# go to the url that is printed in the console
Inspiration
Thousands of methods have been developed to predict stock performance, some taking dozens of parameters and using complicated calculations. However, I realized that the market is ultimately determined by supply and demand, which means the stock is worth as much as the investors value them. I wanted to try a more qualitative approach, using sentimental analysis on stock market news to determine stock performance.
What It Does
Given a stock ticker (i.e. AAPL) it searches NASDAQ.com for related articles and scrapes off all the data. It then cleans the data removing unrelated items (like headers and footers). It then breaks the text into 5000 character chunks and using Azure Text Api it analyzes all the chunks of data. It averages the results and outputs a percentage. I.e. the higher the rating the higher the overall sentiment of news articles, 100% = overwhelmingly positive, 0% = overwhelmingly negative, and 50% = neutral.
Technologies
The back-end is created in Flask, and data scraping is done with beautifulsoup4. Azure Text Api is used to provide analysis.
Challenges
Scraping Data: My original plan was to find all of the links on Stock page on NASDAQ.com and then download the data from there, but the problem was that every page would have over 100 links and only 10 of them were the articles I wanted. I had to filter all of the links by discovering a hidden attribute in all of the articles.
Slow Loading Speeds: The problem was when there were a lot of articles to download, the file sizes could get quite large even if the articles themselves were small (100 articles @ 2mb each = 200mb download). The solution was to parse the HTML using BeautifulSoup4 before the images were loaded. This improved response time by a factor of 10. So now instead of running the algorithm on 10 articles in 10 seconds, 100 articles could be analyzed in the same time.
Future Ideas And Whats Next
In the future I would like to make a new machine learning model to further improve the prediction accuracy. I would implement a Recursive Neural Network based off of Andrej Karpathy's research paper. I would train this model on solely finance related articles and by doing this I believe error could be reduced substantially and the accuracy would be unparalleled.
Another project by Ian Ramzy